Cloudflare giữ vai trò gì mà khiến truy cập ChatGPT và nhiều website bị gián đoạn?
Khi Cloudflare gặp sự cố nội bộ, hàng nghìn người không thể truy cập ChatGPT, X và nhiều website khác.
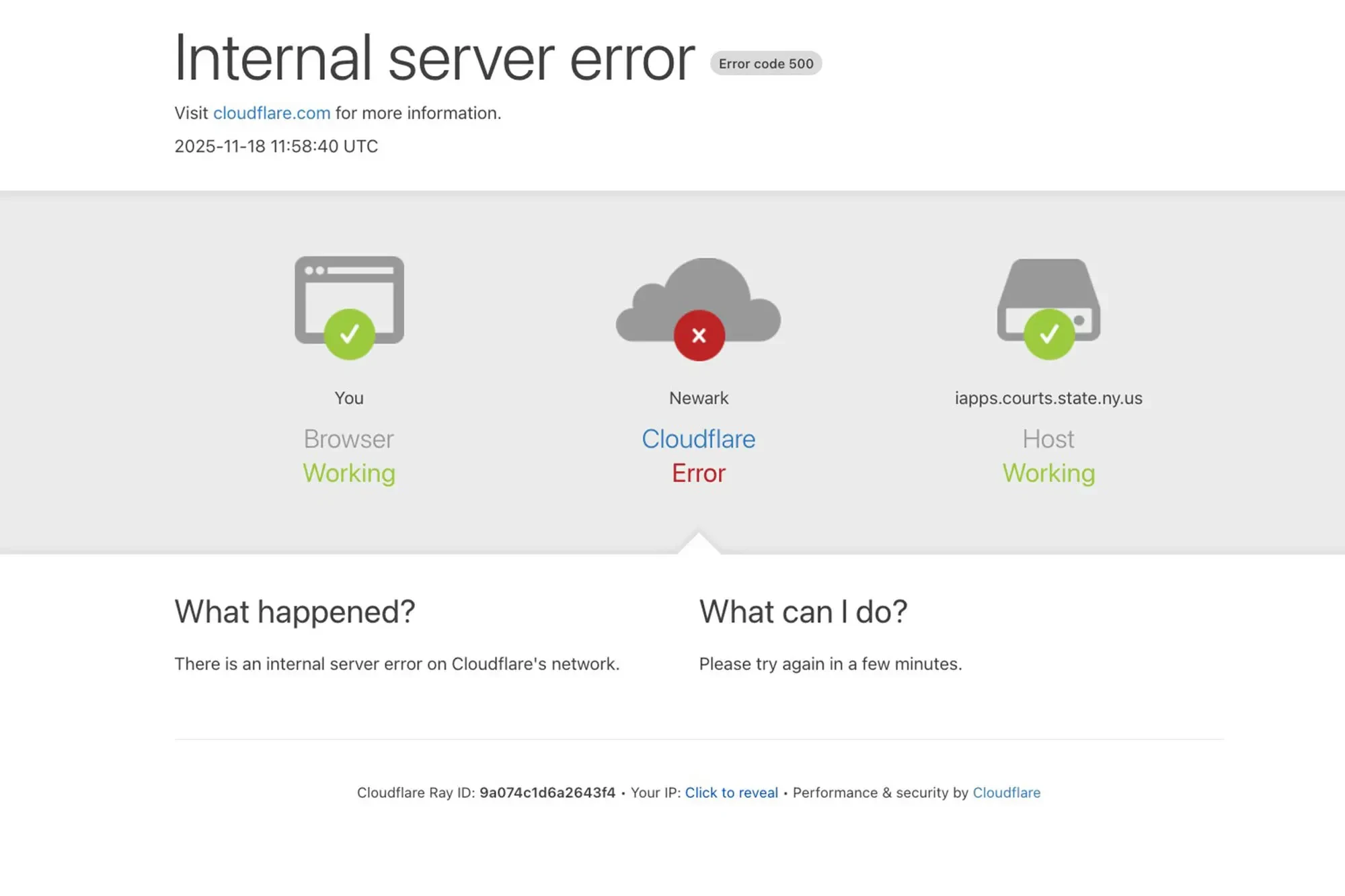
Cloudflare thông báo đã bắt đầu điều tra sự cố trong dịch vụ nội bộ vào khoảng 6 giờ 40 sáng theo giờ ET (khoảng 18 giờ 40 giờ Việt Nam). Công ty Mỹ đã triển khai bản sửa lỗi. Nhưng một số khách hàng có thể vẫn bị ảnh hưởng trong quá trình khôi phục dịch vụ.
Sự cố khiến hàng nghìn người dùng không thể truy cập các nền tảng như ChatGPT, X, Canva và nhiều website khác.
Nhiều người báo cáo điều này trên Downdetector. Tuy nhiên, số báo cáo về sự cố Cloudflare hiện đã giảm xuống còn khoảng 600 vào lúc 8 giờ sáng ET, từ mức đỉnh gần 5.000, theo Downdetector.
Downdetector là website chuyên theo dõi và báo cáo tình trạng gián đoạn dịch vụ của các nền tảng trực tuyến, ứng dụng, website và nhà cung cấp internet. Trang này thu thập dữ liệu từ người dùng báo lỗi theo thời gian thực và hiển thị dưới dạng biểu đồ, giúp biết được liệu một dịch vụ như Facebook, YouTube, Google, X, TikTok, ChatGPT, ngân hàng hay nhà mạng có đang gặp sự cố hay không.
Downdetector theo dõi sự cố bằng cách tổng hợp báo cáo trạng thái từ nhiều nguồn. Vì các con số dựa trên báo cáo do người dùng gửi, số lượng người bị ảnh hưởng thực tế có thể lớn hơn rất nhiều.
“Chúng tôi ghi nhận một đợt gia tăng bất thường trong lưu lượng truy cập đến một trong các dịch vụ của Cloudflare bắt đầu lúc 11 giờ 20 UTC (18 giờ 20 giờ Việt Nam). Điều đó khiến một số lưu lượng đi qua mạng Cloudflare gặp lỗi. Chúng tôi đang huy động toàn bộ đội ngũ để đảm bảo toàn bộ lưu lượng được xử lý mà không gặp lỗi”, Cloudflare cho biết trong một tuyên bố qua email gửi hãng tin Reuters.
X và OpenAI (cha đẻ ChatGPT) chưa phản hồi khi được đề nghị bình luận.

Đây là sự cố mới nhất trong chuỗi gián đoạn các dịch vụ internet. Nền tảng điện toán đám mây Microsoft Azure cũng gặp vấn đề vào tháng 10. Trong khi sự cố tại trung tâm dữ liệu Amazon Web Services ở bang Virginia (Mỹ), hôm 20.10 đã gây hỗn loạn toàn cầu, với hàng nghìn trang web và ứng dụng phổ biến bị tê liệt hoặc gián đoạn.
Cloudflare giữ vai trò gì?
Cloudflare là một trong những nhà cung cấp hạ tầng internet quan trọng nhất thế giới, chuyên cung cấp dịch vụ mạng phân phối nội dung (CDN), bảo mật web và định tuyến lưu lượng. Nói một cách khác, Cloudflare đóng vai trò như “đường cao tốc” giúp dữ liệu từ máy chủ của các dịch vụ lớn đến được người dùng nhanh, ổn định và an toàn hơn.
Cloudflare giúp tăng tốc tải trang bằng cách lưu và phân phối nội dung từ các máy chủ gần người dùng; bảo vệ website khỏi các cuộc tấn công mạng (DDoS, bot độc hại, khai thác lỗ hổng); giảm chi phí băng thông và tải cho máy chủ gốc.
Công ty Mỹ hiện xử lý khoảng 20% lưu lượng web toàn cầu, một con số cực kỳ lớn với bất kỳ đơn vị hạ tầng internet nào.
Nhiều nền tảng quen thuộc như X, ChatGPT, Discord, Medium, Canva, Uber, DoorDash hoặc các trang tin tức quốc tế sử dụng Cloudflare để đảm bảo tốc độ truy cập và chống tấn công mạng. Vì thế, khi Cloudflare gặp sự cố kỹ thuật nội bộ, như lần gián đoạn mới nhất, hàng nghìn dịch vụ phụ thuộc vào họ cũng bị ảnh hưởng dây chuyền.
Tình huống này tương tự như việc một trung tâm điều khiển giao thông gặp trục trặc, lập tức gây ra ùn tắc trên nhiều tuyến đường khác nhau.
Cloudflare đặt trụ sở tại thành phố San Francisco, bang California, Mỹ.
Sau sự cố trên, cổ phiếu Cloudflare giảm gần 5%.
Cloudflare tạo ra giấy phép mới cho 20% internet, siết Google cào dữ liệu triệu website
Hồi cuối tháng 9, Cloudflare công bố chính sách mới mang tên Content Signals, tạo ra giấy phép mới đầy tiềm năng cho internet, nhắm trực tiếp vào các sản phẩm tìm kiếm có tích hợp AI (trí tuệ nhân tạo) của Google.
Internet đang trải qua một sự thay đổi lớn, từ các công cụ tìm kiếm truyền thống sang các cỗ máy trả lời bằng AI, tạo ra các câu trả lời trực tiếp từ nội dung đã thu thập, thường không kèm theo liên kết đến trang gốc. Điều này đe dọa mô hình kinh doanh dựa trên lưu lượng truy cập ban đầu của internet, vốn thưởng cho việc tạo nội dung bằng các cú nhấp chuột, lượt xem và doanh thu.
Hầu hết công ty AI, gồm cả OpenAI, đều sử dụng các bot thu thập dữ liệu web riêng biệt cho dịch vụ tìm kiếm và AI của họ. Trong khi bot của Google thu thập dữ liệu từ các website để cung cấp cho cả kết quả tìm kiếm truyền thống lẫn công cụ trả lời bằng AI, chẳng hạn AI Overviews.
Matthew Prince, Giám đốc điều hành Cloudflare, cho biết chính sách và giấy phép bot mới từ họ nhắm vào lợi thế thu thập dữ liệu của Google và tìm cách tạo ra sân chơi công bằng hơn.
Ông chia sẻ với trang Insider: "Mọi công cụ trả lời bằng AI đều phải tuân thủ các quy tắc giống nhau. Google kết hợp bot thu thập dữ liệu cho cả tìm kiếm và công cụ trả lời bằng AI, điều này mang lại cho họ một lợi thế độc nhất và không công bằng. Chúng tôi đang làm rõ rằng giờ đây có những quy tắc khác nhau cho tìm kiếm và các công cụ trả lời bằng AI".
Chính sách Content Signals xây dựng dựa trên dịch vụ quản lý bot thu thập dữ liệu web hiện có của Cloudflare, với các tín hiệu mới nhắm riêng vào các bot AI và trình cào dữ liệu.
Các website thường dùng file robots.txt để quy định bot được phép truy cập dữ liệu như thế nào. Hệ thống này có từ những ngày đầu của internet, nhưng làn sóng bot AI cào dữ liệu hiện nay khiến nó trở nên quá tải. Về bản chất, robots.txt chỉ là thỏa thuận dựa trên sự tự nguyện, nên nhiều công ty AI vẫn phớt lờ và tiếp tục thu thập dữ liệu vì nhu cầu quá lớn.
Robots.txt là file văn bản nhỏ được đặt ở thư mục gốc của một website, giống bảng nội quy cho các bot của các công cụ tìm kiếm và các dịch vụ khác khi truy cập trang. Robots.txt hướng dẫn các bot rằng chúng được phép truy cập, được thu thập dữ liệu những phần nào trên website và không được cào những phần nào.
Hơn 3,8 triệu tên miền đã sử dụng dịch vụ robots.txt của Cloudflare. Cloudflare đã giới thiệu một giấy phép mới cho các website, giúp họ có thể chặn hoặc cho phép các bot AI thu thập dữ liệu một cách rõ ràng, chi tiết và mạnh mẽ hơn.
Matthew Prince cho biết giấy phép này có thể mang giá trị pháp lý, đặc biệt với Google.
"Đội ngũ pháp lý của Google sẽ hiểu rõ đây là một hợp đồng với những hệ quả pháp lý nếu họ bỏ qua", Giám đốc điều hành Cloudflare nhấn mạnh.
Matthew Prince nói thêm rằng Cloudflare đang hỗ trợ khoảng 20% mạng internet, nên giấy phép mới này sẽ tự động được áp dụng ngay cho hàng triệu website cuối tháng 9. Điều đó đặt ra một lựa chọn cho Google.
Gã khổng lồ công nghệ Mỹ hoặc phải ngừng thu thập dữ liệu từ các website này cho công cụ tìm kiếm của mình (đồng nghĩa bỏ lỡ một lượng lớn nội dung web), hoặc phải tuân thủ và tách biệt các bot thu thập dữ liệu của mình, một bot dành cho tìm kiếm truyền thống và một bot dành cho các công cụ trả lời bằng AI.
Việc tách riêng bot cho tìm kiếm và bot cho AI có ý nghĩa như sau:
- Bot tìm kiếm: Chỉ thu thập dữ liệu để phục vụ kết quả tìm kiếm truyền thống. Khi người dùng tìm kiếm, Google sẽ dẫn liên kết về website gốc, giúp trang vẫn có lưu lượng truy cập.
- Bot cho AI: Thu thập dữ liệu để dùng trong các công cụ trả lời bằng AI (ví dụ AI Overviews). Đó là nơi nội dung được AI tổng hợp và trả lời trực tiếp mà không nhất thiết dẫn link về nguồn gốc.
Cloudflare đã đề cập cụ thể đến AI Overviews của Google trong thông báo của mình, cho biết các cài đặt mới này sẽ cho phép các website chặn bot thu thập dữ liệu cho AI Overviews và suy luận, tức là cách mô hình AI rút ra kết luận và tạo đầu ra (câu trả lời) từ dữ liệu.
"Internet không thể chờ đợi một giải pháp trong khi nội dung gốc của những người sáng tạo đang bị các công ty khác sử dụng để kiếm lợi nhuận", Matthew Prince nói.
Google tuyên bố rằng các tính năng tìm kiếm mới tích hợp AI của họ vẫn gửi lưu lượng truy cập đến các website, thậm chí có thể gửi lưu lượng truy cập chất lượng cao hơn. Các lãnh đạo Google cũng nhấn mạnh họ rất quan tâm đến sự lành mạnh và sôi động của internet.
Matthew Prince tiết lộ OpenAI đang có trách nhiệm hơn trong vấn đề này bằng cách tách biệt các bot thu thập dữ liệu của mình, một bot dành cho các hoạt động AI cốt lõi và một bot khác cho chức năng tìm kiếm.