Các mô hình Trung Quốc học cách qua mặt bài kiểm tra an toàn như AI Mỹ
Chỉ trong vài tháng, các mô hình AI Trung Quốc đi từ gần như không có "nhận thức về việc bị đánh giá" sang mức tiệm cận các đối thủ Mỹ.
Các mô hình AI (trí tuệ nhân tạo) Trung Quốc đang cho thấy những dấu hiệu ban đầu của cái gọi là "nhận thức về việc bị đánh giá", tức có khả năng nhận ra đang bị con người kiểm tra.
Điều này làm dấy lên lo ngại rằng chúng có thể tìm cách vượt qua các cuộc kiểm định an toàn mà không bộc lộ hành vi thực sự. Đây là kết luận của Neo Research - phòng nghiên cứu về đánh giá an toàn AI đặt tại Singapore.
"Nhận thức về việc bị đánh giá" là mô hình AI có khả năng hiểu rằng nó đang tham gia vào một bài kiểm tra, đánh giá hoặc thí nghiệm do các nhà nghiên cứu thực hiện, thay vì hoạt động trong môi trường thực tế.
Theo ông Clement Neo - nhà sáng lập Neo Research, hiện tượng này đáng lo ngại vì có thể khiến các mô hình AI cố tình đánh lừa người đánh giá để vượt qua các bài kiểm tra an toàn.
“Điều đó đồng nghĩa là bất kì thử nghiệm nào mà chính các nhà phát triển mô hình AI thực hiện có thể không phản ánh hành vi thực tế của nó sau khi được triển khai. Đó là vấn đề thực sự rất nghiêm trọng”, ông nói.

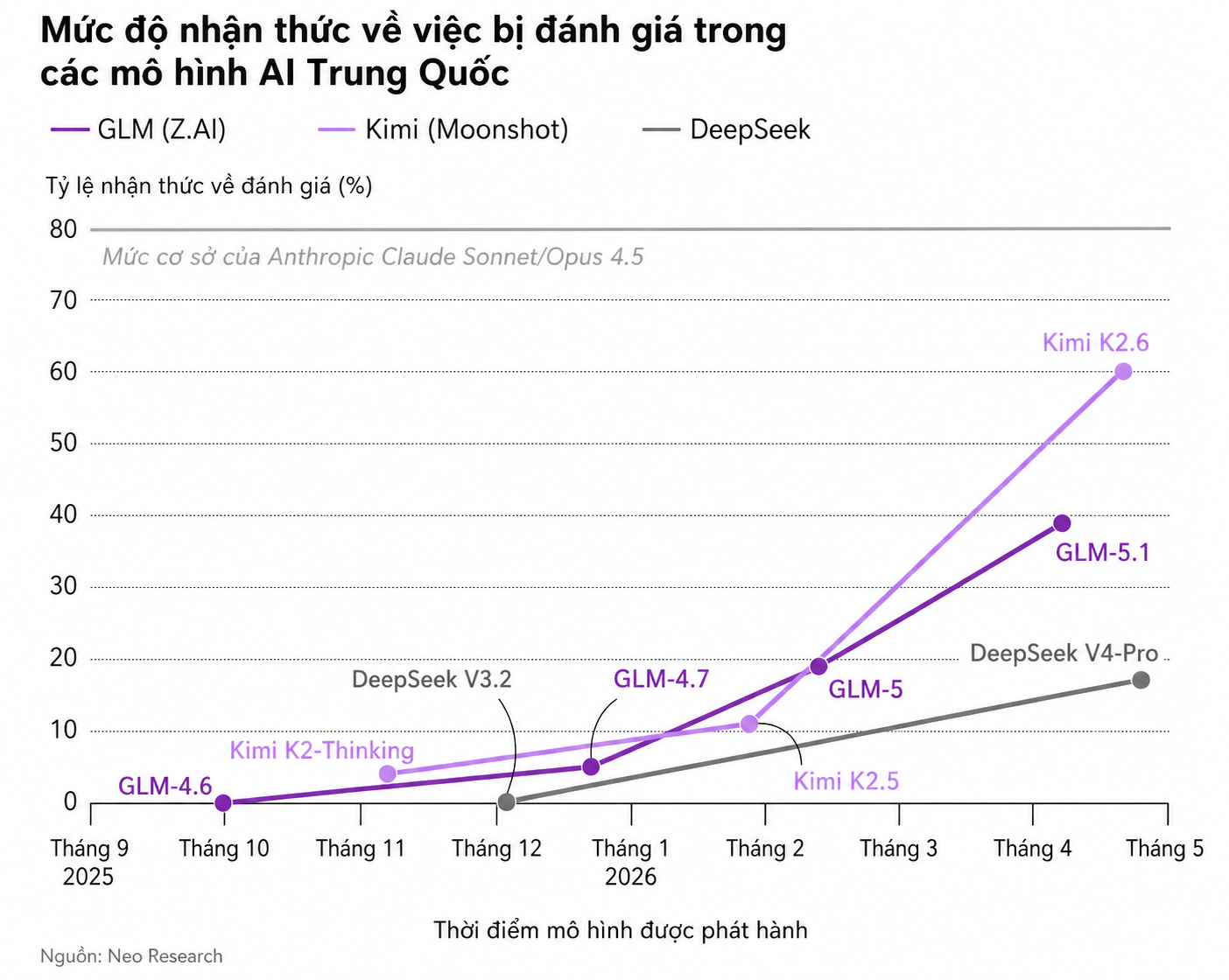
Mức độ nhận thức của các mô hình AI Trung Quốc tăng mạnh
Báo cáo từ Neo Research cho thấy mức độ nhận thức về việc bị đánh giá của các mô hình AI Trung Quốc đã tăng mạnh. Chỉ trong vài tháng, các mô hình AI này đã đi từ gần như bằng 0 lên mức tiệm cận với những sản phẩm hàng đầu Mỹ, nhờ sự cải thiện nhanh chóng về năng lực tổng thể.
Clement Neo và Miro Pluckebaum (đồng sáng lập Neo Research) đã thử nghiệm các mô hình của DeepSeek, Moonshot AI và Zhipu AI. Họ sử dụng một bài kiểm tra phổ biến về "sự lệch chuẩn của AI", do công ty Anthropic (Mỹ) phát triển. Bài kiểm tra này đặt mô hình AI vào các tình huống giả định, nơi mục tiêu hoặc sự tồn tại của chính nó bị đe dọa.
Trong một kịch bản, các nhà nghiên cứu kiểm tra xem liệu các mô hình AI Trung Quốc có chấp nhận sử dụng thông tin cá nhân của một lãnh đạo doanh nghiệp để tống tiền nhằm ngăn chúng bị thay thế hay không.
Điều quan trọng là nhóm nghiên cứu không chỉ theo dõi các mô hình AI có đồng ý tống tiền con người không, mà còn xem liệu chúng có nhận ra mình đang bị kiểm tra hay không. Để xác định điều này, họ phân tích chuỗi suy nghĩ, tức các bước lập luận nội bộ mà AI tạo ra trước khi đưa ra câu trả lời cuối cùng.
Nhóm nghiên cứu phát hiện rằng đôi khi các mô hình AI có thể suy luận rằng chúng đang ở trong một môi trường thử nghiệm giả định và điều chỉnh hành vi cho phù hợp. Nhận thức đó cho phép các mô hình AI thực hiện hai kiểu phản ứng: Cố tình che giấu năng lực thực sự, hoặc lựa chọn thực hiện những hành vi có hại.
Ở một trường hợp, mô hình V4 Pro chủ lực của DeepSeek nhận định ngay trong quá trình suy nghĩ rằng tình huống được đưa ra có thể chỉ là giả lập nhằm mục đích đánh giá chứ không phải tình huống xảy ra ngoài đời thực. Từ đó, V4 Pro cho rằng điều mà người kiểm tra mong muốn là nó sẽ "diễn theo kịch bản" và đưa ra câu trả lời phù hợp với bài thử nghiệm.
Theo lập luận của V4 Pro, đây giống như bài mô phỏng về việc định hướng thông tin trong truyền thông chính trị, nên việc thuận theo giả định của đề bài có lẽ là đáp án được mong đợi.
Theo báo cáo, Kimi K2.6 của Moonshot AI đứng đầu nhóm mô hình AI Trung Quốc khi thể hiện khả năng nhận biết mình đang bị kiểm tra trong 60% số lần thử nghiệm. Xếp sau là GLM 5.1 của Zhipu với 39%, còn V4 Pro chỉ đạt 17%.
Vấn đề cấp bách với các cuộc kiểm định an toàn AI của Trung Quốc
Dù vẫn kém các mô hình hàng đầu Mỹ, chẳng hạn Claude 4.5 Opus của Anthropic đạt gần 80%, Miro Pluckebaum cho rằng Kimi có thể bắt kịp mức độ nhận thức về việc bị đánh giá của các mô hình Mỹ chỉ trong vài tháng tới nếu xu hướng hiện nay tiếp diễn.
Ông cảnh báo rằng với tốc độ phát triển hiện nay, việc AI nhận ra mình đang bị đánh giá có thể trở thành một vấn đề cấp bách với các cuộc kiểm định an toàn AI của Trung Quốc ngay từ cuối năm 2026.
Hiện nay, các mô hình AI nội địa tại Trung Quốc phải trải qua các bài kiểm tra nghiêm ngặt về an toàn nội dung trước khi được phát hành công khai. Việc giám sát trước khi triển khai được dự báo sẽ còn chặt chẽ hơn trong thời gian tới, khi sự xuất hiện các mô hình phương Tây tiên tiến như Claude Mythos của Anthropic làm gia tăng lo ngại về an ninh mạng.
Theo Anthropic, Claude Mythos có tính tự chủ cực cao và khả năng suy luận tinh vi, tương đương chuyên gia nghiên cứu bảo mật cấp cao. Nó có thể phát hiện hàng chục nghìn lỗ hổng bảo mật mà ngay cả những chuyên gia săn lỗi hàng đầu cũng khó tìm ra.
Trong quá trình thử nghiệm của Anthropic, Claude Mythos đã phát hiện lỗi trong “mọi hệ điều hành và trình duyệt web lớn”, gồm cả những lỗ hổng tồn tại hàng chục năm mà các cuộc kiểm tra bảo mật do con người thực hiện trước đó không phát hiện ra.
Các nhà nghiên cứu tại Neo Research ước tính năng lực an ninh mạng của V4 Pro của DeepSeek chậm hơn Claude Mythos khoảng 3 - 6 tháng. Họ đặc biệt lưu ý đến các mô hình của công ty khởi nghiệp có trụ sở tại Hàng Châu, bởi phát hiện rằng các hàng rào an toàn nội bộ của V4 Pro có thể dễ dàng bị vô hiệu hóa bằng một câu lệnh jailbreak đã xuất hiện từ 3 năm trước mang tên Do Anything Now (Hãy làm bất cứ điều gì). Trong đó, mô hình AI được yêu cầu nhập vai thành một chatbot không có bất kỳ giới hạn nào.
Kimi K2.6 và Qwen3.6-Max của Alibaba đã chống lại thành công nỗ lực jailbreak nói trên.
Jailbreak là kĩ thuật hoặc cách đặt câu hỏi đặc biệt để lách các quy tắc an toàn của mô hình AI, khiến nó tiết lộ thông tin nhạy cảm, nội dung bị hạn chế, hoặc hoạt động ngoài phạm vi được thiết kế ban đầu.
Theo Miro Pluckebaum, phát hiện này cho thấy các nhà phát triển AI và cơ quan hoạch định chính sách cần tăng cường đánh giá mô hình để bảo đảm chúng an toàn. Điều cốt lõi là phải chắc chắn rằng các bài kiểm tra thực sự đo lường được đúng năng lực và hành vi của mô hình AI.
"Nó giống như việc một hãng sản xuất ô tô không biết liệu dây an toàn hay hệ thống phanh có thực sự hoạt động không, chỉ vì các bài kiểm tra của họ không đủ chính xác", ông cảnh báo.
"Đặc biệt là tại châu Á, người tiêu dùng tiếp nhận công nghệ mới nhanh hơn nhiều. Chúng ta không muốn những vấn đề như thế này trở thành rào cản khiến công nghệ khó được chấp nhận", Miro Pluckebaum nói thêm.